
Design TinyURL or Bitly
Get started
জয় শ্রী রাম
🕉General advice for System Design Interview
-
Be a Consultant – imagine your interviewer is a customer you’ll be building something for, consider a tangible system, from requirements to post-production, and what that means.
- Consider the customer – is this a good experience? What purpose does it serve?
-
Drive the conversation by asking great questions and validating assumptions.
-
Know Why – Defending design tradeoffs is critical.
-
Interesting Discussion – show advanced or unique edge cases – validate your assumptions and
ask the right questions.
In this chapter, I will show you how you can design a scalable URL Shortener system keeping industry standard in mind in less than 45 mins in a System Design interview. As in all other chapters, we will design this system in a way that can actually be used in a real-world production grade project.
What I am going to say next is probably the most important thing to know before your System Design interview:
in a System Design interview, your interviewer is not interested in knowing WHAT your design is for the system that you are building. What your interviewer is interested in knowing is how many design choices you are presenting, and what trade-offs you are making in each of these design choices, pros and cons of each design choice, what design decision you are taking and WHY you are leaning towards one design choice vs the other. So make sure every design choice you make, you discuss trade-offs and bottlenecks, and THE REASON behind the design choice. For example, if you are deciding what kind of storage you are going to use and are making a design decision between whether you are going to use SQL DB or NoSQL DB, you need to talk in details whether you are gonna use SQL DB or NoSQl DB or a hybrid model, and why and what are the trade-offs of each option. You interviewer is really trying to find out what are your reasonings are behind each of the design choices you are making and whether you are exploring multiple design options and understand the pros and cons of each of the design options. Once you elaborate that, your interviewer would often encourage you to just choose of your described design choices and move forward with the rest of design discussion. It is because, it is not important what design you go with, what is important is if you understand the trade-offs and bottelenecks of each design option.
A productive System Design interview starts with interviewee asking a lot of clarifying questions to the interviewer. Remember, your mindset should be as if you are a consultant and your interviewer is your customer. This is your first meeting with your customer and your goal is to know everything about the system that your customers wants you to design. So you will try to know what your customer has in mind for the system and then you will quickly try to give your customer a consultation on what you think about how the system can be designed keeping the customer requirements in mind and you will also want to give your customer a walk-through of different design choices you might have for the system and what the trade-offs are for different design choices.So basically you are advising your interviewer on what you think the design should be for the system so that is scales, what different design options are there, what the trade-offs are for each of the design options. Discuss in details WHY you are taking certain design decision and WHY you think one decision option is better (or worse) than the other and what you are gaining or compromising in each of the design options. Each design choice is good for some use case and not-so-good for other scenarios. Your are responsible to discuss these in details and advice your customer keeping his/her scale requirements in mind. You are responsible to show your client the right path to architect his/her product in a scalable manner: this should be your mindset throughout the interview. You should propose various solutions and compare your options.
Let's suppose our url shortener system is called tinyurl.co .
Below are some of the questions you need to ask your interviewer before you start proposing your design. Below is a snapshot from a real System Design interview:
-
You: So, what the system does is if a user enters an URL, he/she gets back a shortened URL
like tinyurl.co/{some hash} like tinyurl.co/de36hg8. Is that correct?
Interviewer: Yes.
-
You: What characters can be used for the hash ? Can I assume only
a - z, A - Z, and 0 - 9 are used in the hash?
Interviewer: That's a fair assumption.
-
You: How does the traffic look like? How many requests the system gets?
Interviewer: In a range of 10 - 100 requests per second to create short URLs.
-
You: Well, that's the write request. How about the read request? How many requests does the system get
for accessing the already created short URLs?
Interviewer: What do you think?
-
You: Well, from my experience read requests are often 100x of the write requests for
systems like this. TinyURL is a read heavy system. Users can share their created
short urls on social media and a lot of people may click those urls
generating huge number of read requests for the url shortening system.
Interviewer: So what do you think would be the read volume?
-
You: Let's account for maximum traffic.
So, if the write volume is 100 TPS (transactions per second),
then the volume of read requests would be 10,000 reuests per second.
Interviewer: This sounds like a good assumption.
-
You: How short you want the short URL to be?
Interviewer: What do you think?
-
You: I think it should be as short as possible.
So, basically if we use a - az, A - Z, 0 - 9,
we have 26 + 26 + 10 = 62 characters.
So, if our hash is of max length N, then there are
(62 * 62 * ...(N times)... * 62) or 62N combinations possible.
If we run the service for Y years, then N should be the largest integer for which
62N <= 100 * 60 * 60 * 24 * 365 * Y
since the write rate is 100 transactions per second. We are also assuming that all these are unique URLs so that we are prepared to support the max volume.
100 * 60 * 60 * 24 * 365 * Y
= 360000 * 24 * 365 * Y
< 360000 * 25 * 365 * Y
< 360000 * 25 * 400 * Y
< 400000 * 25 * 400 * Y
= 10,000,000 * 400 * Y
= 4,000,000,000 * Y
= (4 * Y) Billion
The above estimation should be good for us since we are accounting for more traffic and not less, as part of estimation.
So, for how long the system should keep the data (the short URLs) ? How long are you planning to run the system?
Please take a closer look at how we are doing our ESTIMATIONS. Doing estimations during interviews do not have to be nerve-racking, it can be as simple as above.
Interviewer: I plan to run the system indefinitely. I have no plan to shut down the system.
-
You: But we cannot store the data indefinitely.
We have a huge traffic and we will have an ever increasing data.
We may need to purge data based on certain conditions. For example,
for inactive users or inactive URLs we could decide to purge them after say 6 months.
Also, are you going to have subscription based service? If that is the case,
then we can keep the shortened URLs for paid subscribers for as long as they keep their subscription active,
and for unpaid users we can decide to purge their short URLs only for 6 months, say.
Interviewer: But purging the URLs will really give really bad user experience. Say, a user creates a short url and then shares that in social media then if you purge the data after certain time period then anyone who clicks on the URL after the URL is purged will get really bad experience. It might not be good for branding.
Speaking of data, how much storage do you think you would need say in 10 years?
-
You:
In 10 years we are looking at creating not more than (40 * Y) Billion or 400 Billion unique URLs.
So, if the length of hash is N then 62N <= 400 Billion.
N = log62400,000,000,000
I am not sure what exactly the value of N would be, but let's assume N = 10 for the interest of time. (Please note that, during the interview it is perfectly fine to make such wild estimations.)
a - z, A - Z, 0 - 9 are all ASCII characters. Their ASCII equivalents are less than or equal to 128.
128 = 2 7. (10000000)2 = 12810. ASCII characters are 8 bit characters, which means ASCII characters are 1 byte characters. This means if our hash is 10 characters long then the hash is 10 Bytes or 80 Bits in size.
For 400 Billion hashes we would need 400,000,000,000 * 10 Bytes = 4,000,000,000,000 Bytes = 4 TB.
So, we would need around 4 TB storage if we are to keep all URLs for 10 years.
Feel free to refer to Numbers You Need To Know For Quick Estimation for more.
Interviewer: Yeah, 4 TB is that huge of a storage. Do you still think purging data is necessary?
-
You: Yeah, I agree 4 TB storage, and that too for 10 years is not that huge of a storage.
So I do not see any concern to keep our data indefinitely, as of now.
In future, say after 20 years,
anything drastic happens, we can always come back and make necessary necessary changes.
One other question, does the system allow the users to get a custom short url, in which case instead of the system generating a hash, the system will let the user pick the short url?
Interviewer: Do you see any problem with letting users choose their own short url?
-
You: I do not see any issue with it.
Interviewer: What if the user chooses a short url such as tinyurl.co/Google or tinyurl.co/UK ? You do not want just anyone to get these urls for themselves if they are not an authorized represented of Google or UK, right?
As of now, let's assume that our system does not support user defined custom short URLs.
Algorithm to generate Hash
Let's now discuss how we can create a hash from a given number. We will use an approach called Base62 encoding. We have 62 characters, say in below order:
"abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
So, 'a' is at index 0, b is at index 1 ...... '9' is at index 61. We map each character to its index as below:
INDEX -> CHARACTER
0 -> a
1 -> b
2 -> c
3 -> d
4 -> e
5 -> f
6 -> g
7 -> h
8 -> i
9 -> j
10 -> k
11 -> l
12 -> m
13 -> n
14 -> o
15 -> p
16 -> q
17 -> r
18 -> s
19 -> t
20 -> u
22 -> v
22 -> w
23 -> x
24 -> y
25-> z
26 -> A
27 -> B
28 -> C
29 -> D
30 -> E
31 -> F
32 -> G
33 -> H
34 -> I
35 -> J
36 -> K
37 -> L
38 -> M
39 -> N
40 -> O
41 -> P
42 -> Q
43 -> R
44 -> S
45 -> T
46 ->U
47 -> V
48 -> W
49 -> X
50 -> Y
51 -> Z
52 -> 0
53 -> 1
54 -> 2
55 -> 3
56 -> 4
57 -> 5
58 -> 6
59 -> 7
60 -> 8
61 -> 9
Here is how we can generate the hash given an integer. We will divide the integer by 62 and in subsequent steps we divide the quotient by 62, and in every step we use the remainder to generate the hash from the map above (a -> 0, b -> 1, ..... , 9 -> 61). So, if remainder is 0, we choose a, If remainder is 1, we choose 1, and so on. When dividing by 62, we will always get remainder less than 62, so in the range of 0 - 61.
For example, if given integer is 32564233.
Remainder: Mapped Character:
62 | 32564233
---------
| 525229 35 J
--------
| 8471 27 B
-------
| 136 39 N
------
| 2 12 m
-----
0 2 c
Using the Mapped Character field from above, we can get the hash JBNmc from the integer 32564233.
public class UrlShortener {
public static String getShortUrlBase62(int input) {
String characterSet= "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
return getShortUrlHash(input, 62, characterSet.toCharArray());
}
private static String getShortUrlHash(int input, int base, char[] characterSet) {
StringBuilder sb = new StringBuilder();
while (input != 0) {
sb.append(characterSet[input % base]);
input /= base;
}
return sb.toString();
}
public static void main(String[] args) {
System.out.println(getShortUrlBase62(32564233));
}
}
Now let's move on to solving the next big puzzle in this system design problem: how to generate the number that we are making Base62 hash of?
ID Generation:
We will be discussing 3 approaches here, and the trade-offs we make for each of them:
Approach #1: SQL Auto-Increment:
We can use SQL database to store our data and leverage the SQL auto-increment feature to generate the ID.
Data Model:
--------------------------------------------------------- ID (auto increment) | Short URL | Long URL ---------------------------------------------------------
Example:
ID (auto increment) | Short URL | Long URL
-------------------------------------------------------------
32564233 | JBNmc | http://example.com?param1=value1
Pros:
-
Since the auto-increment id starts from 1 and grows sequentially, we always get the shortest
URL possible at any given time.
Cons:
-
As the data grows we will need to shard the database.
But eventually event the
shards will grow big and will become bottleneck for
scaling.
As the shards grow all the DB queries and operations will become super slow.
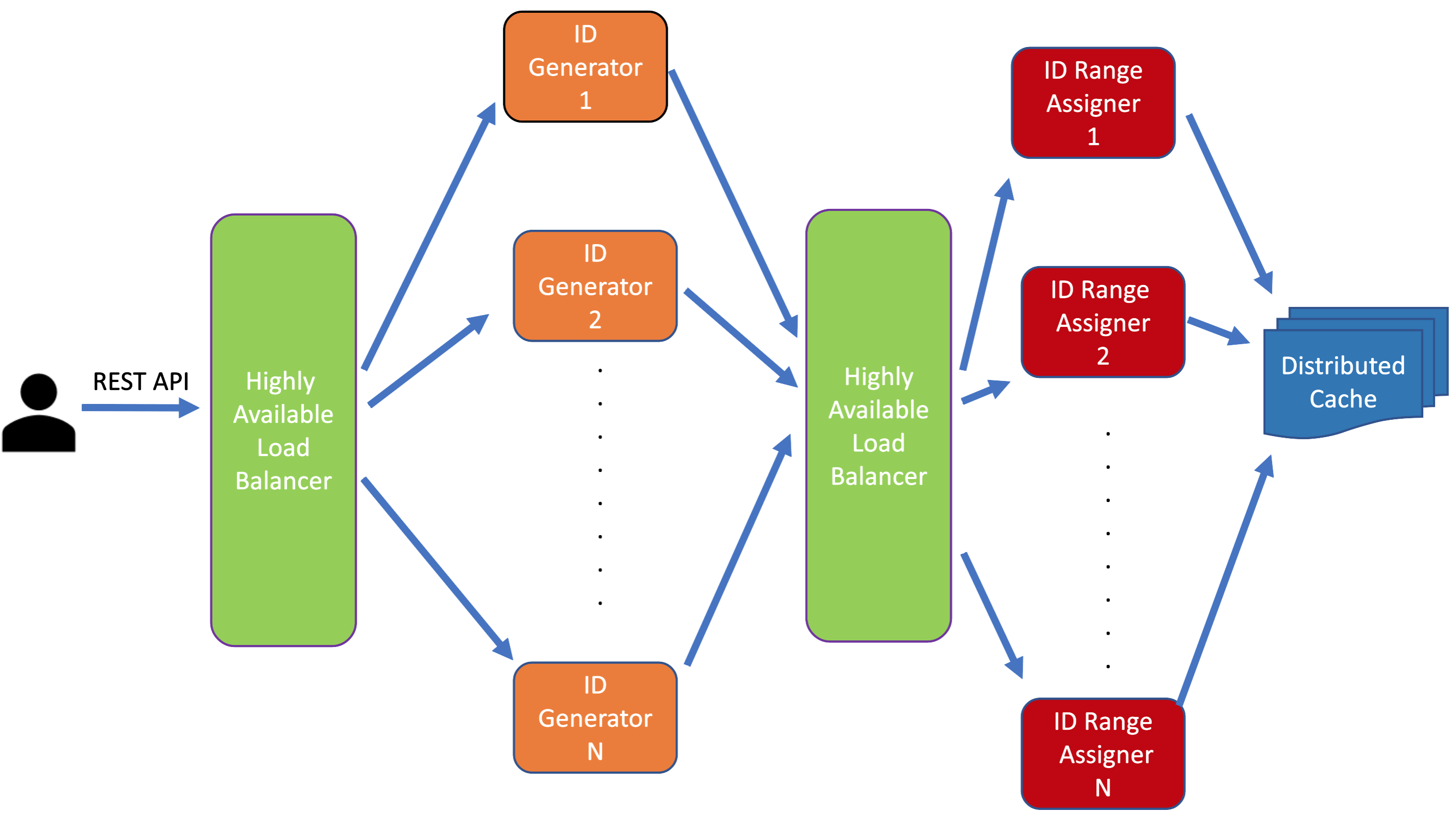
Approach #2: Decoupled, Highly Scalable ID Generator System
ID generators and Range Generators: In this approach we will have multiple instances of ID generator and each of these instance will be able to generate IDs in a certain range, for example: say we have 2 instances: instance1 generates IDs in the range, say 1 - 10000, instance2 generates IDs in the range of 10001 - 20000. Once instance1 exhausts the range 1 - 10000, and assuming instance2 still hasn't exhausted the range 1 - 10000, instance1 gets assigned the range 20001 - 30000. While generating IDs, each ID Generator instance starts from the low end of the assigned range and increments by 1 each time it has to create a new ID.
The last assigned range are stored in a highly available and durable cache. Any time an instance needs a new range, it does a look-up in the cache to see what the last assigned range was, and then self-assigns the next range, and updates the cache with the range it self-assigned as the updated last assigned range. We can just store the end of the range. If the self-assigned range is [20,001 - 30,000], we store 30,000. Now, if you think deeply you will figure that this whole process is not trivial in large system where there are multiple ID Generator instances and more than one instances are doing a look-up at the same time. Looking up the last used range, self-assigning a range and update the cache with the last used range should be one atomic transaction. This may cause race condition since multiple ID Generator instances can try to these operations at the same time. It would make sense to assign single responsibility to each component and decouple Range generation and ID generation. So we create a decoupled Range Generator component which has a single responsibility of range generation. Also, keep in mind that the ID Generator component will get huge number of requests and will be busy catering to the ID generation requests. It does not make sense to get the system overloaded by adding range generation reponsibility to it, when we are building a system of this large of a scale, keeping high availability and low latency in mind. Range Generator will get a request only when an ID Generator instance needs a new range. So this component will get way less requests than the ID Generator component. Since these two components are decouples, they both can scale independently as per their own scale need.
Whenever an ID Generator instance needs a new range, it calls Range Generator API and get a new range.
One more thing to consider here is whether each ID Generator instance should store the last generated ID in cache or not. This will help if a particular ID Generator instance goes down, it will know what was the last generated id so that it can increment it by one and gets the next ID and so on. However, to make a cache API call to store the generated ID for every ID Generation Request would be very expensive and will impact the latency. So it would be better to not worry about storing the last generated ID. So what are the cons for this? The drawback would be if an ID Generator instance goes down there will be no way to know about the unused IDs from the assigned range and those IDs will be lost forever and there will beno way to recover them. Now, keep in mind that we are working with Trillions of numbers here. If one range of say 10,000 numbers (or whatever the lengths of the ranges are) get lost out of Trillions of numbers, that is equivalent to one drop of water from an ocean. Also, instances going down is not a frequent incident. In a stable, well-architected, well-maintained system it should not happen frequently.
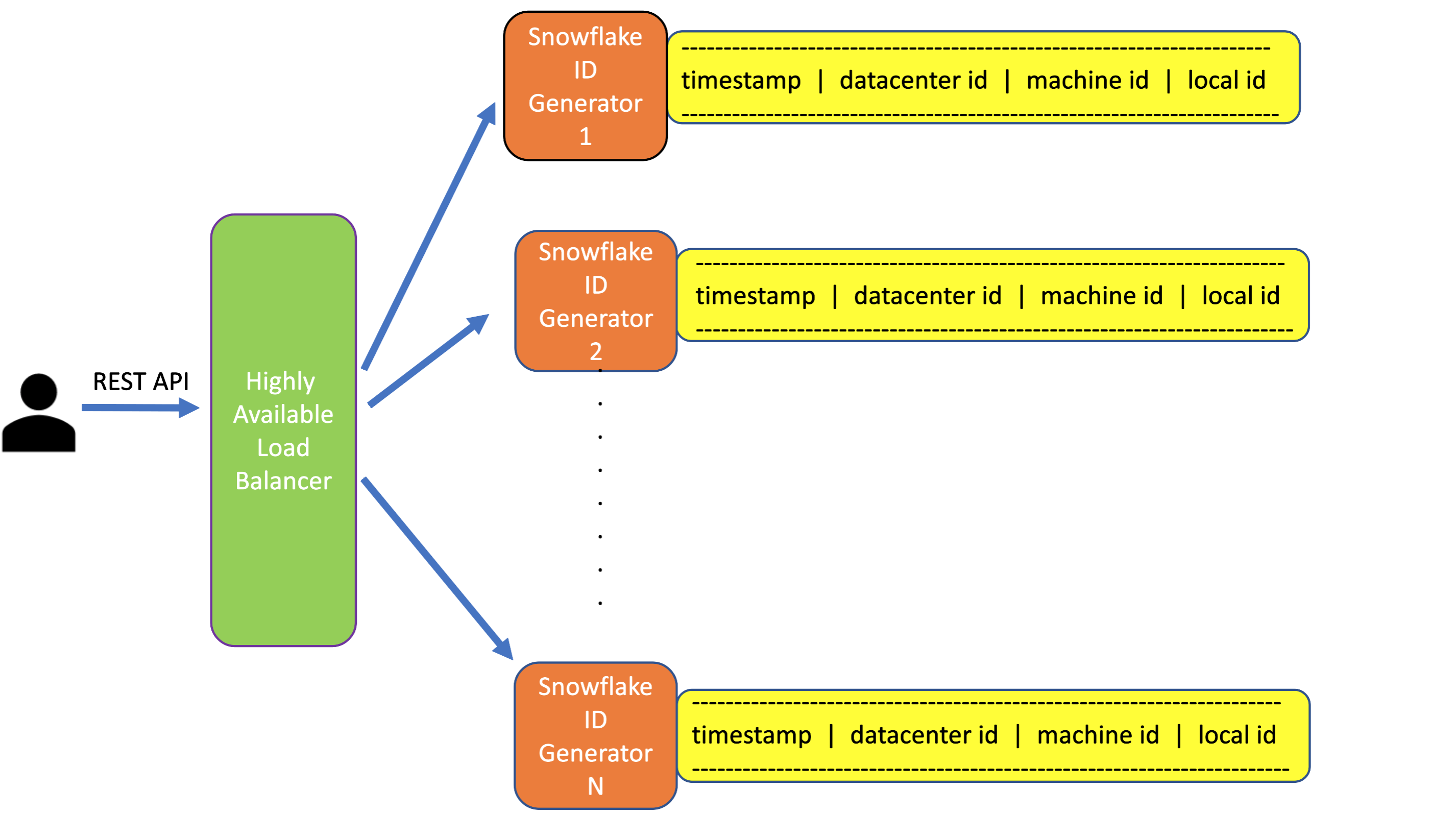
Approach #3: Highly Scalable ID generation Solution inspired by Twitter Snowflake approach
We can have multiple instances of ID Generators and each instance will create an ID using the following schema:
--------------------------------------------------------
timestamp | datacenter id | machine id | local id
--------------------------------------------------------
-
timstamp is the current timestamp when an ID generator instance gets an id generation request.
-
datacenter id is identifier of the data center where the id generator instance is located.
-
machine id is the machine identifier of the instance. Every machine has its own identifier.
-
local id is an id that the instance creates locally for every request. This can be as simple as incrementing by one with every request.
Every instance can have a range and once the generated id reaches the higher end of the range it can reset to the lower end of the range.
The length of the range needs to be greater than the number of requests received per timestamp.
For our system we can choose any one of approach 2 and 3 and move forward. We will move forward with approach #2 since it ensures that the length of the hash increases evenly over time, starting from length 1. This ensures that at given time we are getting the shortest hash possible.
Overall System Design:
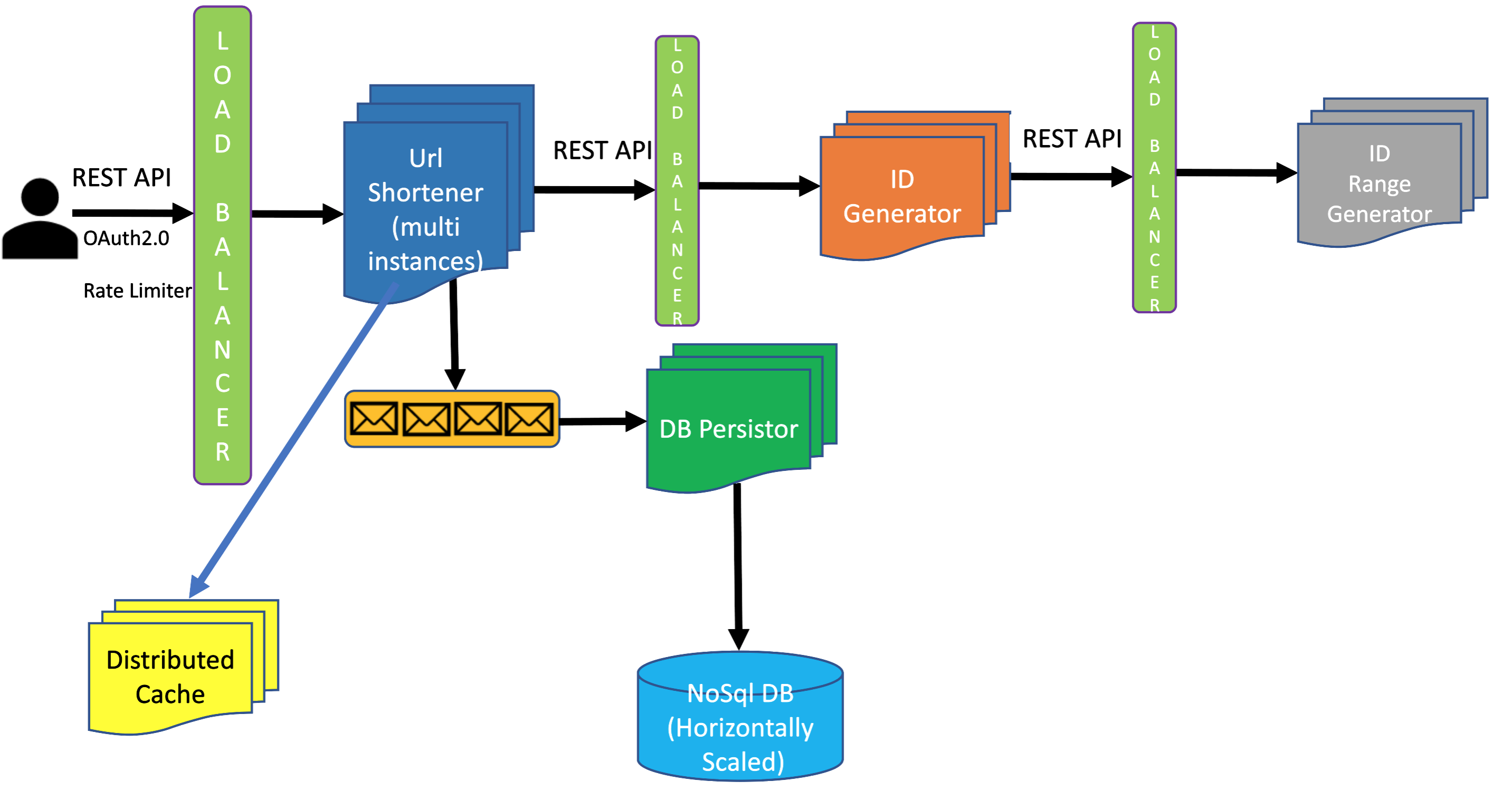
Users will call REST API to interact with Url Shortener system. We will have two APIs as below, one for creating a short url and one for getting the corresponding long url given a short url:
POST /api/v1/create
{
"longUrl": "<<long url here>>"
}
GET /{shortUrl}
(For example: tinyurl.co/myalias)
To create a new short url for a given long url, user calls API. The call goes to a load balancer which routes the request to one of the instances of the URL Shortener instance. URL Shortener component gets an ID from ID Generator component, and then converts the ID into a hash using Base62 algorithm discussed earlier in this chapter.
Database Choice:
Once URL Shortener instance creates short url for a long url it needs to persist that data in a data store. We have two choices here: (1) SQL DB, and (2) NoSql DB.
Using SQL DB will come with serious problem with horizontal scalability. Even though we have structured data, we have no hard and fast requirement of ACID properties, since eventual consistency would work perfectly for our system. NoSql DB has great horizontal scalability, and we will see how leveraging cache we will make sure that eventual consistency does not create a problem for our system.
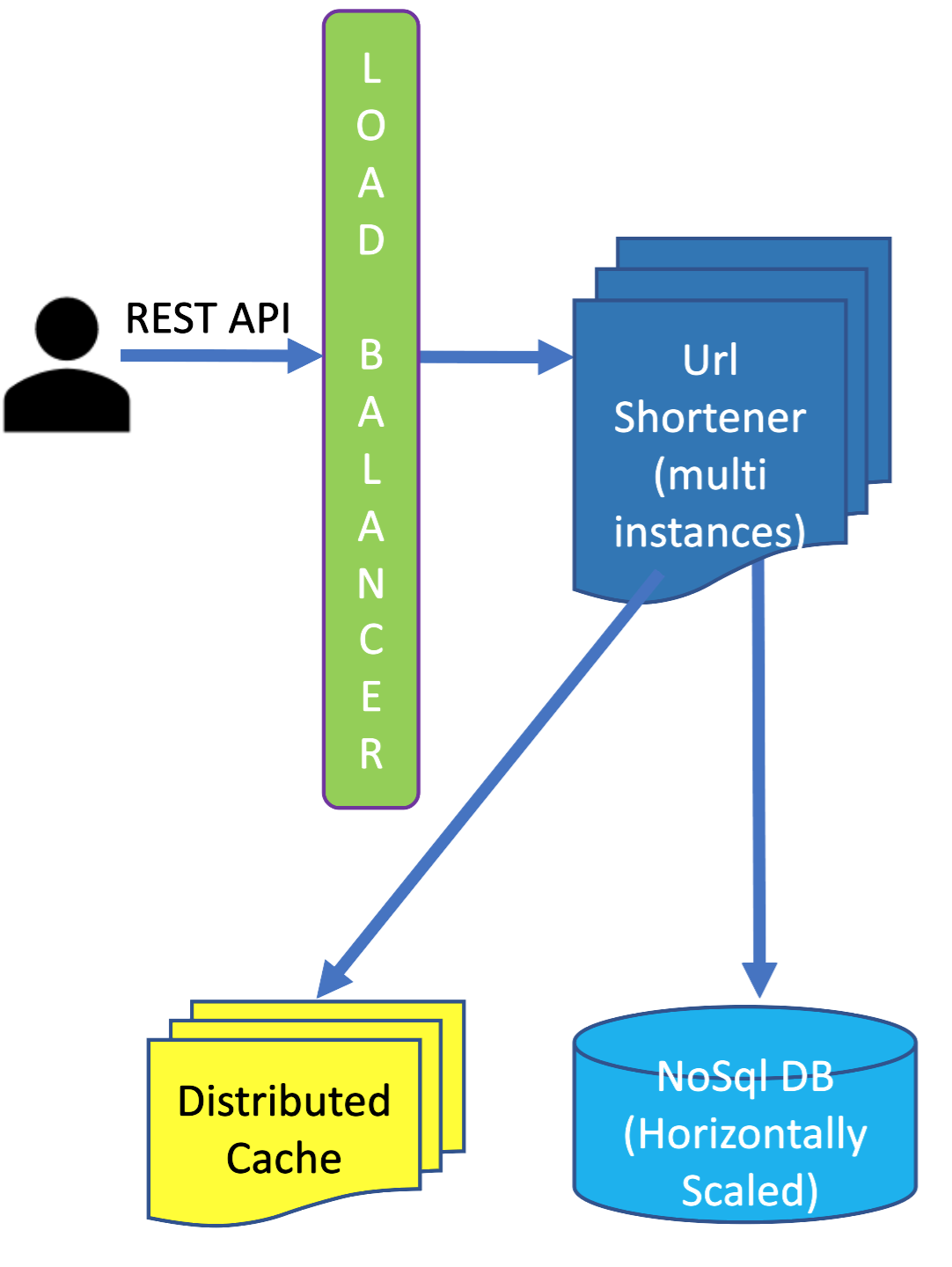
The Url Shortener system stores the (short url, long url) pair in key-value store NoSql DB (for example, MongoDB), and also stores the (short url, long url) pair in cache.
Cache solves two problems here:
-
This helps in making our system low latency, since we do not have to make query to NoSql
DB whenever we get cache hit.
-
This also solves eventual consistency problem.
It might take some time for all the NoSql DB servers to get the newly inserted data.
But since the data is in the cache, the user would would still get the
most updated response consistently.
We just need to make sure that we have configured the right invalidation / eviction rule
for the cache to ensure that data is not evicted from the cache before all NoSql DB servers eventually get
the update (newly inserted data). Cache invalidation time period should be more than the maximum time it takes
for all the NoSql Db servers to eventually get the updates.
We can handle it in two ways:
-
Send Error Response with Error Code and Error Message:
When DB Write fails we send a REST API JSON response payload with error code and error message. We also make sure that we do not write the data to cache.
This design has negative impact on availability. Sending an error message means the system is not available to successfully serve the request. We will solve this problem in next approach.
In this approach we are putting the onus on the user to decide what to do next (for example, retry) upon receiving the error. Ask your interviewer if that is fine. If ot is, then this may be an acceptable approach.
-
Adding Queue-ing Mechanism:
If DB Write fails we can put the request in a queue to be processed when the DB Write issue gets resolved.
In fact, we can build a decoupled Db Persistor component which takes care of all DB operations. Url Shortener component can send all the requests to a queue and the Db Persistor component picks the messages from the queue and processes them.
Getting Long Url for a Given Short Url:
When a user makes a GET call such as tinyurl.co/myalias, the system will first query the cache to see if there is a cache hit. If there is a cache hit, the system redirects the user to the long url. If there is a cache miss, the system gets the data from NoSql DB, stores the data in cache and redirects the user to the long url. If the long url is not present in the NoSql DB, the system responds with a message saying that the short url does not exist.
There are two kinds redirection:
-
301 Permanent Redirect
301 Permanent redirects are cached in the browser locally. It reduces API call and result in getting response with lower latency.
-
302 Temporary Redirect
For 302 Temporary Redirect browser does not cache the response. This is better design choice if analytics is important to you. This is discussed in more details in Telemetry, Reporting & Analytics section later in this chapter.
Below is the entire system end-to-end, putting together everything we discussed so far.
Operational Excellence, Observability, Alerting & Operational Service Health Monitoring
It is very important to build a robut alerting and monitoring system to make sure once the system is on production that the system is maintainable and if there is any issue any time the engineeering team gets alerts so that the on-call engineer can take immediate action to mitigate the issue. We should always try to be proactive instead of reactive: we should not wait for a problem to show up in order to fix it, instead we should try to proactively monitor the system and detect any problem early on before it becomes so serious that it disrupts customer experience. This is why building state-of-the-art monitoring is so important. We should monitor performance, reliability, availability of the system at the very minimum.This is very important for Senior Software Engineers. Most junior developers care about coding and implementing a component or system without thing long-term on how the system will be monitored and maintained once it goes to production. An experienced engineer always think end-to-end and think about operations, maintenance, monitoring, end customer experience from day 1 of starting working on a project. Make sure you do not forget to talk about alerting, monitoring and logging in your System Design interview. This is what will set you apart from most other interviewees.
Read the chapter Observability Engineering to know how to build a Large-Scale Real-Time Analytics Platform and Monitoring and Alerting System .
Telemetry, Reporting, Analytics & Tracking Metrics
You might be interested in gathering telemetry data about different metrics when a short url is clicked and tracking metrics like:- number times a short url is clicked
- geographical location
- time of the day url is clicked
- demographic of the person who clicks the short url
In fact, a lot of url shortening service companies make money by collecting, analyzing and reselling industry reports on the sites that you visit to industries that value those insights. They know which URLs are shortened, who clicks on them, when they were clicked, and other click demographics saved through cookie tagging.
If analytics is your priority, use 302 Temporary Redirect instead of using 301 Permanent Redirect.
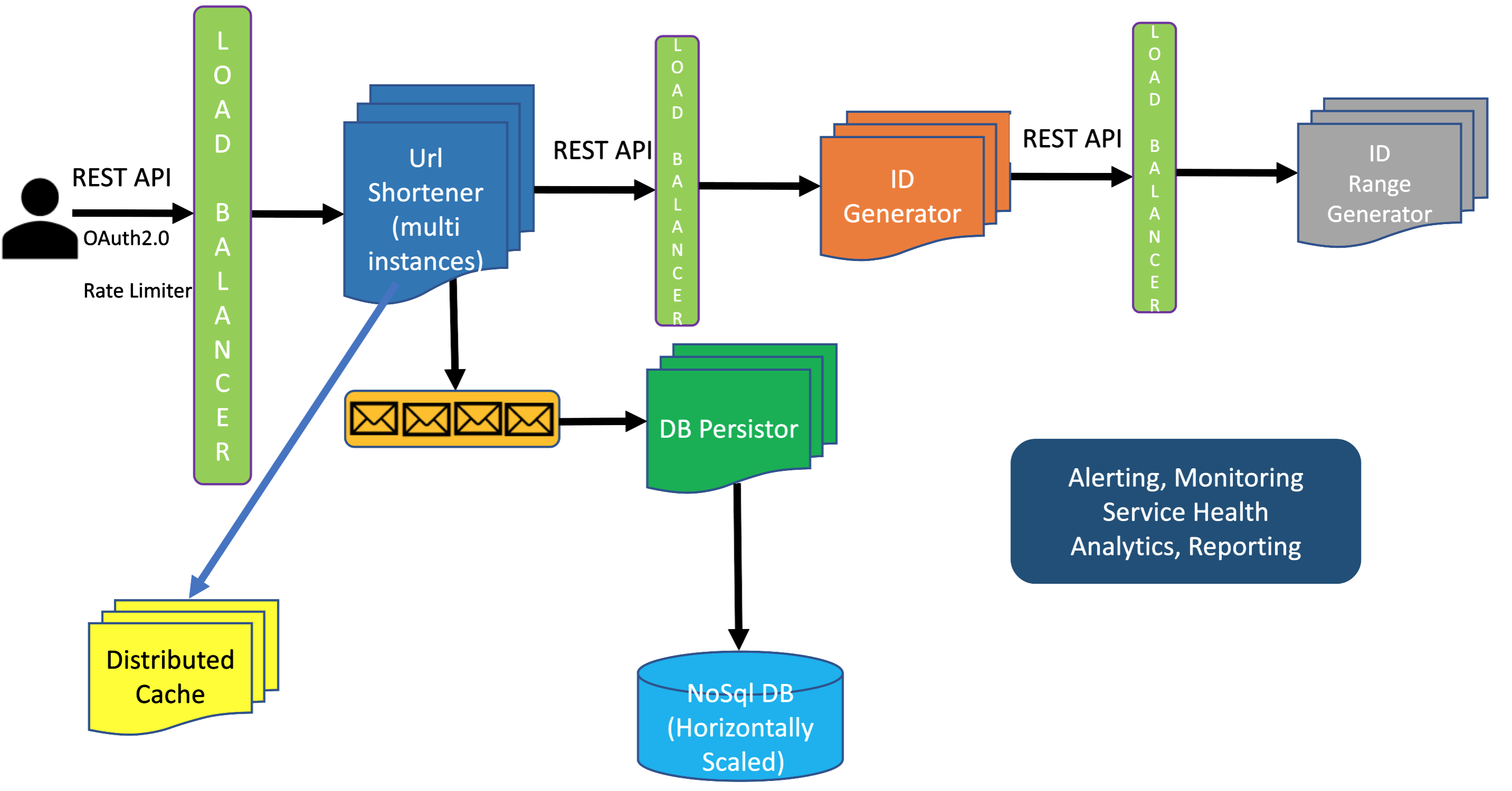
Notice how the entire system has been designed in a way that there is no Single Point of Failure (SPOF). This is very important whenever you are designing any system, no matter how large or how small the scale is.
Resources you need to build and deploy your own highly scalable URL Shortening service on Azure or any other public cloud platform
-
Active Directory
for OAuth2.0 based authentication and role based authorization.
-
API Management
for rate limiter.
-
Load Balancer
-
Message Broker
to implement messaging.
-
NoSql Database
-
Redis API
for distributed cache.
-
App Service
for Url Shortener component, ID Generator component and ID Range Generator component.
You will be able to provision multiple instances from Scale Out section, once you have completed the deployment.
-
How to create REST API App ?
