
Multithreaded Web Crawler
Get started
জয় শ্রী রাম
🕉#1. Web Crawling
Problem Statement:
Given a url startUrl and an interface HtmlParser, implement a Multi-threaded web crawler to crawl all links.Return all urls obtained by your web crawler in any order.
Your crawler should:
Start from the page: startUrl
Call HtmlParser.getUrls(url) to get all urls from a webpage of given url.
Do not crawl the same link twice.
The HtmlParser interface is defined as such:
interface HtmlParser {
// Return a list of all urls from a webpage of given url.
// This is a blocking call, that means it will do HTTP request and return when this request is finished.
public List
getUrls(String url);
}
Note that getUrls(String url) simulates performing a HTTP request. You can treat it as a blocking function call which waits
for a HTTP request to finish.
Solution:
The code below is implemented using all the concept introduced in How to Write Production Grade Concurrent Program ? chapter. So if you haven't read that chapter already, I highly recommend you to do so.The most important thing to notice here is that:
htmlParser.getUrls(url) returns a list of all urls from a webpage of given url.
This is a blocking call, that means it will do HTTP request and return when this request is finished.
This means htmlParser.getUrls(url) is a blocking method
and should constitute a task and let it run in the background while
we process already gotten URLs. For every new url we get we should create a task (i.e, create a Callable) and submit to a Thread Pool and
get a future. Since we will be getting a lot of new urls and need to create task for every one of them
we should create a queue that keeps all the futures, and process the newly found urls as the
tasks in the queue are completed.
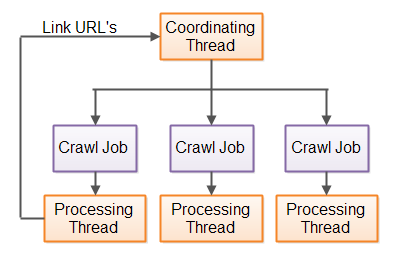
Below is the template we have discussed in the chapter How to Write Production Grade Concurrent Program ? and would adhere to that:
// Create appropriate Thread Pool
private final ExecutorService pool = Executor.newCachedThreadPool(); // call 1 of 4 static factory methods in Executor as appropriate
// Define Task (tasks generally have associated latency)
Callable<V> task = new Callable<V>() {public V call() { ..define task.. }};
// Submit the task to the thread pool for execution in background
// and get a Future back to get the state of the task at any point of time
Future<V> future = pool.submit(task);
// Get the result of the task to actually be able to utilize the result of the task
try {
V taskResult = future.get();
}
catch (InterruptedException | ExecutionException ex) {
}
Let's look at the complete solution now:
Login to Access Content
#2. Web Crawling with Same Hostname
Problem Statement:
Given a url startUrl and an interface HtmlParser, implement a Multi-threaded web crawler to crawl all links that are under the same hostname as startUrl.Return all urls obtained by your web crawler in any order.
Your crawler should:
Start from the page: startUrl Call HtmlParser.getUrls(url) to get all urls from a webpage of given url. Do not crawl the same link twice. Explore only the links that are under the same hostname as startUrl.
http://example.org:8080/foo/bar#bang
As shown in the example url above, the hostname is example.org. For simplicity sake, you may assume all urls use http protocol without any port specified. For example, the urls http://leetcode.com/problems and http://leetcode.com/contest are under the same hostname, while urls http://example.org/test and http://example.com/abc are not under the same hostname.
The HtmlParser interface is defined as such:
interface HtmlParser {
// Return a list of all urls from a webpage of given url.
// This is a blocking call, that means it will do HTTP request and return when this request is finished.
public List getUrls(String url);
}
Note that getUrls(String url) simulates performing a HTTP request. You can treat it as a blocking function call which waits for a HTTP request to finish. It is guaranteed that getUrls(String url) will return the urls within 15ms. Single-threaded solutions will exceed the time limit so, can your multi-threaded web crawler do better?
Solution:
Login to Access Content
Must Read:
- How to Write Production Grade Concurrent Program ?
- How to Prevent Deadlock ?
- Synchronizers
- How to Test Concurrent Program ?
